
System Design Interview by Alex Xu
System Design Interview
目录
设计 YouTube:DAG 任务调度 设计 YouTube:DAG 任务调度
- 重要组件:元数据存储、转码服务、视频存储、CDN、API 服务
- 重要概念:流式传输(边下边播)有对应的协议
- 视频转码:DAG 调度一系列任务,视频、音频、元数据,视频检查、缩略图生成、添加水印、编码等
- 错误处理:重试、兜底、告警、扩容等
- 成本优化:针对长尾,热门走 CDN 冷门走存储,冷门少编码、按需编码
主流流式传输协议
- HTTP 自适应流(点播 / 直播主流)
- HLS(HTTP Live Streaming)
- 苹果主导,基于 HTTP/TCP,将视频切为ts 分片(2–10 秒),用m3u8索引管理
- 支持自适应码率(ABR)、跨终端、CDN 友好、兼容性极强
- 延迟:普通版10–30 秒,低延迟版(LL-HLS)可至3–5 秒
- DASH(Dynamic Adaptive Streaming over HTTP)
- MPEG 标准,通用型自适应协议,切片为 MP4/TS,索引为MPD
- 比 HLS 更灵活,适配更多编码 / 加密 / 码率策略,被视为下一代通用协议
- 延迟:普通版10–30 秒,低延迟版(LL-DASH)可至3–5 秒
- HTTP-FLV
- 基于 HTTP 封装 FLV,延迟3–5 秒,适合直播拉流,浏览器需插件 / 播放器支持
- HLS(HTTP Live Streaming)
- 实时 / 推流协议(直播专用)
- RTMP/RTMPS
- Adobe 开发,基于 TCP,低延迟(1–3 秒),主要用于主播推流到服务器
- 浏览器原生不支持,需 Flash / 播放器,现多用于推流而非分发
- WebRTC
- 浏览器原生实时通信,延迟 <400ms,适合视频会议、低延迟互动直播
- SRT
- 低延迟、抗丢包,适合专业直播 / 广电传输,延迟 <1 秒
- RTSP/RTP
- 控制 + 传输分离,多用于监控、IPTV,需专用服务器,防火墙穿透差
- RTMP/RTMPS
- HTTP 自适应流(点播 / 直播主流)
常见视频网站技术方案
- YouTube
- 点播 / 直播分发(观众端):HLS 为主,DASH 为辅,适配 HTML5 播放器与多终端
- 直播推流(主播端):RTMP/RTMPS为主,也支持 HLS、DASH 推流
- Bilibili
- 点播 / 直播分发(观众端):DASH 为主,HLS 兼容,适配多终端与自适应码率
- 直播推流(主播端):RTMP为主,部分场景用 HTTP-FLV 拉流
- 行业主流协议现状
- 点播 / 大规模直播分发:HLS 与 DASH 双主流,HLS 兼容性更强、DASH 更灵活
- 直播推流:RTMP/RTMPS仍是事实标准,WebRTC、SRT 在低延迟场景快速崛起
- 低延迟互动直播:WebRTC、LL-HLS、LL-DASH成为趋势
- YouTube
直播流媒体与点播的异同
- 相同点
- 核心分发协议通用:HLS/DASH均可用于直播与点播,均支持ABR、CDN 分发、多终端兼容
- 均需视频转码、切片、元数据管理、缓存 / CDN等基础架构
- 不同点
维度 点播(VOD) 直播(Live) 内容源 预录制、存储在服务器 实时采集、边录边传 延迟要求 高(10–30 秒可接受) 中 / 低(普通 1–30 秒,互动 < 1 秒) 用户控制 完整(暂停、快进、后退) 有限(仅暂停 / 播放,无快进) 协议侧重 分发优先(HLS/DASH) 推流 + 分发并重(RTMP 推流 + HLS/DASH 分发) 架构差异 转码后永久存储、按需拉取 实时转码、实时分发、无永久存储 错误处理 可重试、容错空间大 低延迟、快速恢复、不可长时间重试
- 相同点
- Directed Acyclic Graph 有向无环图
- DAG 就是一套 “有先后顺序、没有循环、可并行” 的任务依赖关系图
- DAG 任务调度 = 根据 DAG 定义的依赖关系,自动按顺序 / 并行执行一批任务,并处理:依赖、重试、失败、超时、资源分配、状态流转
- 它解决的核心问题:一堆任务之间有复杂依赖,我不想手动一个个跑,也不想写一堆 if/else,让调度器自动帮我安排。
- DAG 调度的核心能力
- 任务依赖管理
- 分布式执行
- 容错与重试
- 资源调度
- 可视化与监控
- 事件触发
- DAG 调度的通用工作流程
- 定义 DAG:用代码 / 界面画出任务和依赖
- 提交 DAG:交给调度系统
- 调度器解析:计算哪些任务可运行(依赖满足)
- 放入任务队列
- Executor / Worker 拉取执行
- 更新状态
- 触发下游任务
- 全部完成 → DAG 结束
- 失败 → 重试 / 告警 / 终止下游
- DAG 调度典型应用场景
- 视频 / 音频媒体处理(YouTube、B 站、抖音):典型 DAG 密集型场景,任务多、依赖复杂、必须并行
- 大数据 ETL / 数据仓库:每天几万个任务,必须 DAG 调度
- 机器学习流水线 MLOps:一步错,全流程作废,必须强依赖
- CI/CD 构建发布:Argo Workflows / Tekton 都是 K8s 上的 DAG 调度
- 批量计算、离线任务
- 主流开源 DAG 调度工具
- Apache Airflow(最主流、行业标准):Python 定义 DAG,灵活、生态极强、支持几乎所有系统
- Apache DolphinScheduler(国产、易用、可视化):拖拽式 DAG、中文友好、企业级稳定
- Argo Workflows(K8s 原生):适合 CI/CD、微服务任务、云转码
- Taier(大数据专用、分布式):分布式 DAG 调度系统,专注大数据任务管理
- Goflow(轻量级、Go 语言):轻量级 DAG 调度与监控平台,Go 编写、部署极简
设计 YouTube
加载中...
设计搜索自动补全系统:前缀树 设计搜索自动补全系统:前缀树
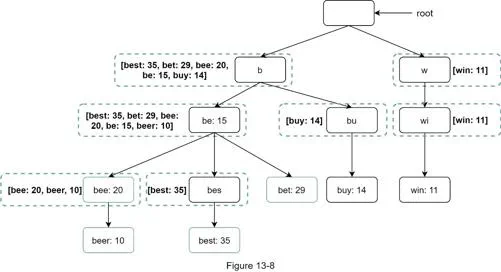
- 重要组件:前缀树(Trie)、数据收集服务、查询服务
- 前缀树每个节点缓存前k个查询,Trie 缓存于内存中,磁盘上的存储可将其序列化后用文档存储,也可以直接键值存储有助于增量更新缓存
- 构建Trie的数据通常来自分析或日志服务,不需要实时构建/更新前缀树,异步构建即可
- 优化:限制前缀长度、分片存储、流处理支持实时热门查询
设计 YouTube
加载中...
设计聊天系统:分布式键值存储 设计聊天系统:分布式键值存储
- 三类服务端推送技术的优缺点是什么?轮询、长轮询、WebSocket(最终采用)
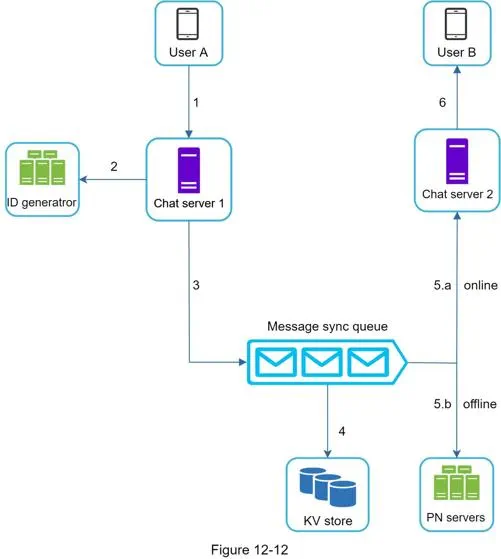
- 核心组件:通用登录、注册等能力的无状态服务、转发和暂存消息(键值存储)的有状态服务、集成第三方的应用未运行时的通知服务、持久性键值存储
- 在线状态为什么用心跳检测比长连接是否断连更好?网络频繁断开重连是可能存在的
- 为什么非要用键值存储,不用 MySQL?
- 消息数据量爆炸,读写压力极大:社交聊天日消息可达百亿级,关系型数据库(MySQL)扛不住这种并发写入 + 海量存储,索引会急剧膨胀,查询长尾旧消息性能暴跌。
- 访问模式极度适配键值存储:聊天只高频读最近消息,偶尔随机查历史(搜索、跳转),键值存储天然支持高吞吐写入、低延迟随机读、水平扩容,关系库做不到。
- 一对一聊天读写比是一比一:发消息 = 写,看消息 = 读,纯键值读写性能远超关系型数据库的事务、联表开销。
- 工业界已验证:Facebook Messenger(HBase)、Discord(Cassandra)、微信聊天记录均用键值存储,是行业标准方案。
- 键值存储存消息,会不会丢失?
- 不会丢,反而比普通 MySQL 更可靠,键值存储本身就是分布式持久化存储,不是内存缓存:
- 消息写入先落盘,不是存在内存里;
- 集群默认多副本(如 3 副本),单节点挂了不丢数据;
- 支持 WAL 预写日志、故障自动容错、数据自愈;
- 配合聊天系统的消息确认机制(客户端 ACK + 服务器重试),进一步杜绝丢失。
- 所谓的 “丢失”,是把键值存储当成 Redis 内存缓存了,而这里用的是持久化键值存储(HBase/Cassandra/LevelDB 系列),和数据库一样可靠。
- 不会丢,反而比普通 MySQL 更可靠,键值存储本身就是分布式持久化存储,不是内存缓存:
- 跨地区 / 多机房怎么处理?
- 分布式键值存储天生支持跨区域多活部署:数据分片 + 跨区域副本、最终一致性、异地多活、就近写入与读取。
- 内存型 KV(如 Redis):数据主要放内存
- 优点:极快、微秒级、支持复杂结构
- 缺点:
- 内存贵,存不了海量冷数据
- 持久化只是附加功能(AOF/RDB),不是设计核心
- 分布式扩容麻烦,不适合存几十 TB 的聊天历史
- 适合:缓存、在线状态、会话、限流、排行榜
- 持久化分布式 KV(如 HBase):数据优先落磁盘,内存只做缓存
- 天生分布式、可水平扩容到几百台机器
- 设计目标就是:海量存储 + 高写入吞吐 + 数据不丢 + 长期保存
- 代表产品:
- HBase(Facebook Messenger 用):分布式、可扩展、列式 KV 数据库;基于 Hadoop 生态,强持久化;海量存储,稳定性极强;支持按范围 scan(拉取最近 100 条消息);部署重,依赖 Hadoop
- Cassandra(Discord 用):去中心化分布式 KV,高可用之王;没有主节点,全部节点对等;写入性能在所有 KV 里第一梯队;一致性是最终一致(聊天完全够用)
- RocksDB / LevelDB(嵌入式高性能 KV):本地高性能嵌入式 KV 存储引擎;常用来存:用户收件箱、本地消息队列、离线消息;微信的很多聊天组件就基于它
- TiKV(国产新一代分布式 KV)
维度 Redis(内存 KV) HBase/Cassandra(持久化分布式 KV) 数据位置 内存为主 磁盘为主,内存缓存 存储容量 小(GB 级) 极大(PB 级) 持久化 附加能力 核心设计目标 数据可靠性 一般,丢盘风险 极高,多副本 + WAL 分布式扩容 复杂 简单,线性扩展 跨区域支持 弱 极强 适合场景 缓存、在线状态、热点数据 永久聊天历史、海量消息 成本 极高(内存贵) 低(用普通硬盘)
- 既然不用 Redis 存历史消息,那它用在哪?
- 存储在线状态(user_id → online/offline)
- 存储用户会话、连接信息
- 缓存最近 N 条消息(提升读取速度)
- 存储心跳、服务发现元数据
- 做简单的消息暂存
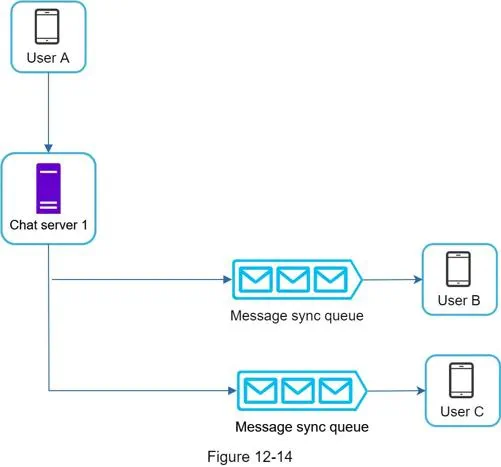
- 消息同步队列的核心用途:
- 解耦发送方与接收方
- 实现离线消息暂存
- 支撑多设备消息同步
- 群聊消息分发
- 它在系统里的位置:用户客户端 → 聊天服务器 → 【消息同步队列】 → 键值存储 + 接收方聊天服务器
- 属于聊天服务层内部的中间组件
- 介于聊天服务器、存储、推送服务之间
- 它是 “真实的消息队列(Kafka/RabbitMQ)” 吗?
- 不一定是重型 MQ,分两种实现,文档里是 “逻辑队列”:
- 小型群聊(≤100 人)→ 逻辑队列(轻量实现)
- 不用独立部署 Kafka/RabbitMQ,直接在键值存储里用 “用户收件箱” 模拟队列
- 比如给每个用户建一个user_inbox列表,消息 ID 追加进去,本质就是 KV 里的一个列表结构,不是独立 MQ 服务。
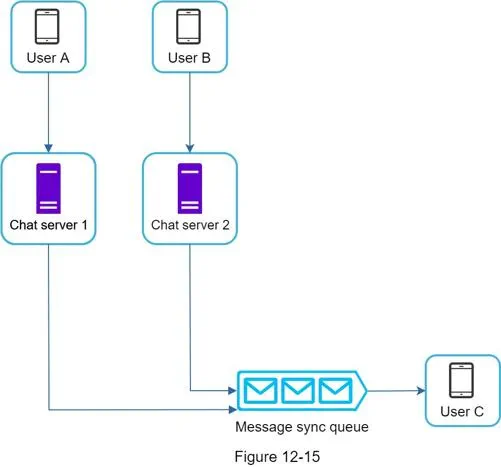
- 超大规模群聊 → 重型 MQ(Kafka)
- 万人以上大群才会用专业消息队列做分发。
- 开销会不会很大?开销极低,完全可控,原因:
- 消息仅文本,体积极小:单条文本消息几百字节,百万消息也就几百 MB,存储 / 传输开销可以忽略。
- 小群复制成本极低:群上限 100 人,一条消息复制 100 份,对现代服务器无压力。
- 异步处理,不阻塞主线程:队列是异步消费,不会造成聊天服务器阻塞。
- 只存消息 ID,不存全量消息:队列里只存message_id,真正消息体存在 KV 里,进一步降低开销。
- 离线用户才排队,在线用户直接推送:不会无意义堆积消息。
设计聊天系统
加载中...
