
DDIA by Martin Kleppmann
数据密集型应用系统设计
目录
存储与检索 存储与检索
- 一个极简数据库道尽了联机事务处理的本质:存储与检索
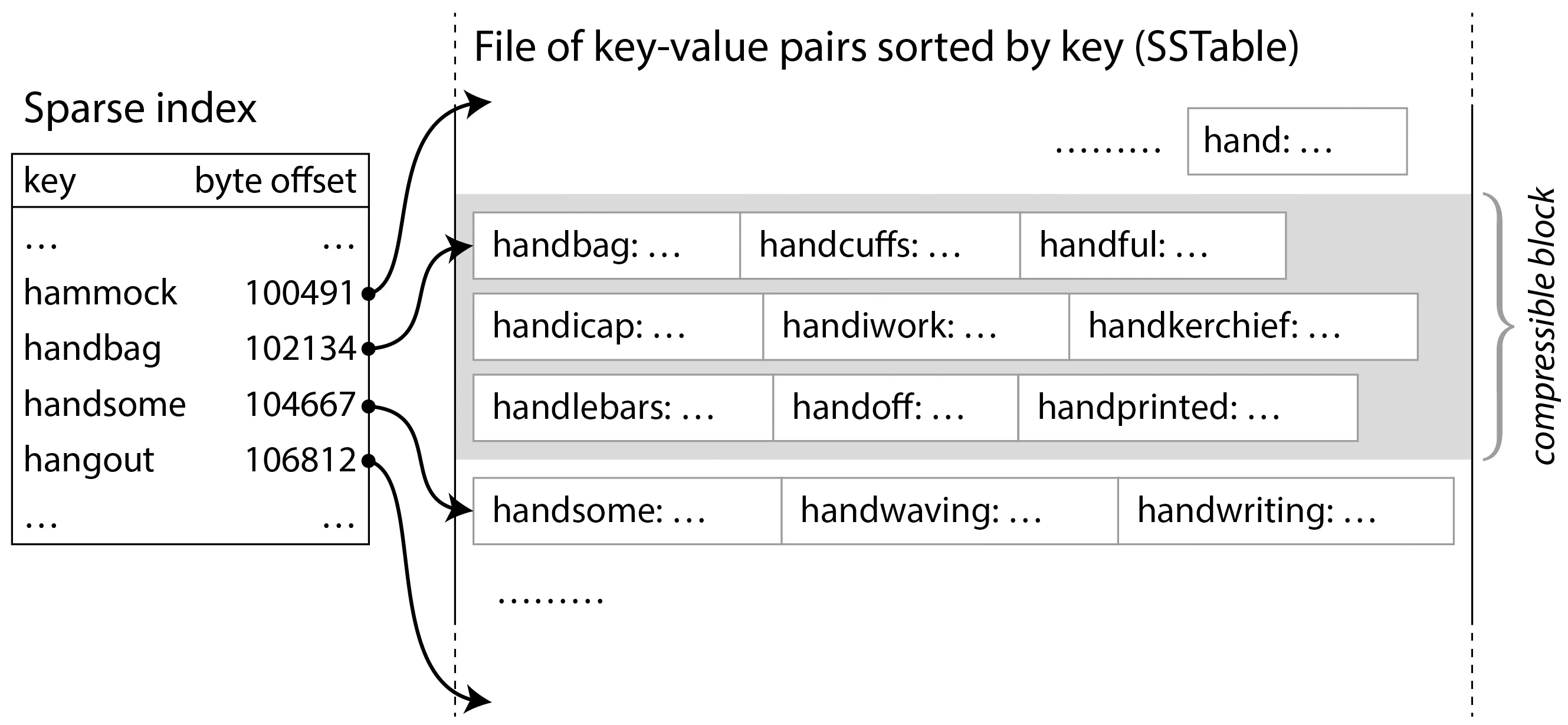
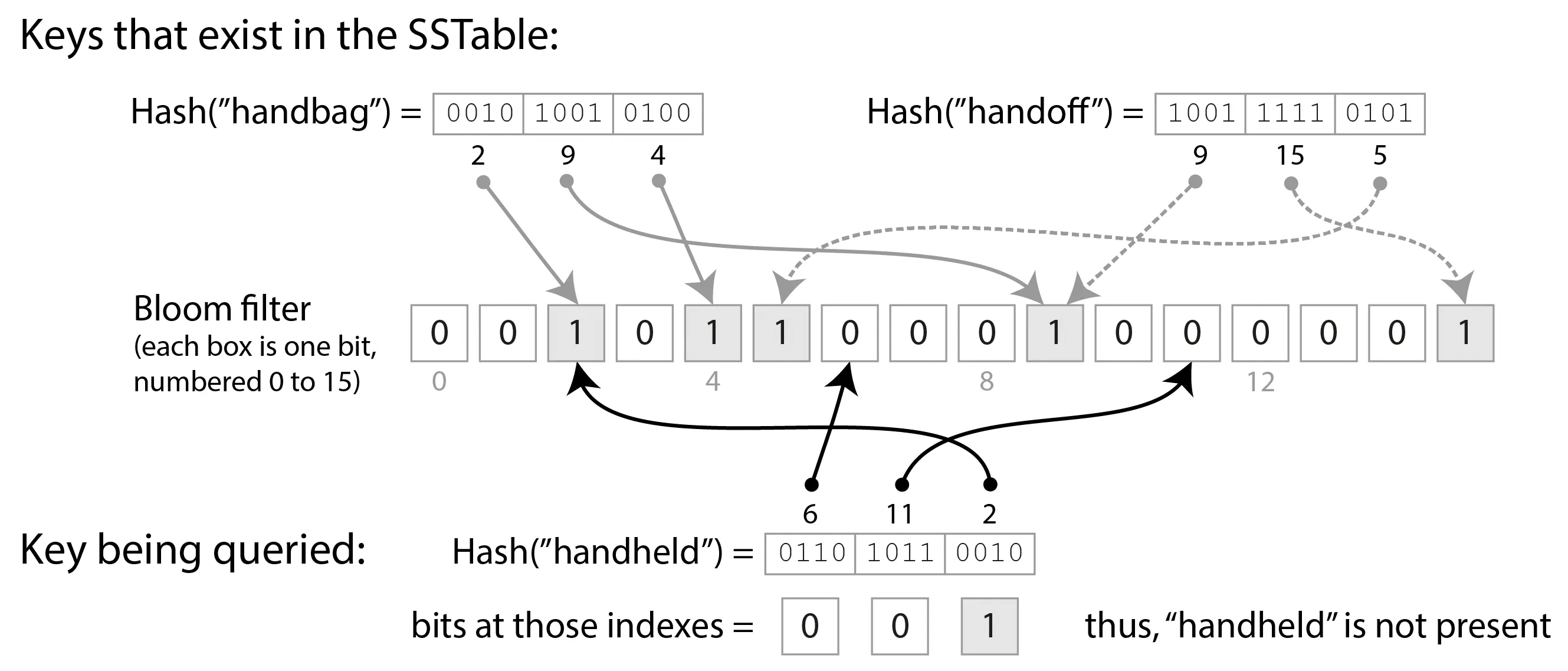
- 日志结构存储的核心流程是什么?MemTable、SSTable、LSM、布隆过滤器、合并压实
- 什么是稀疏索引?只存储部分键的索引,不保存所有键,给有序键分组,存每组的第一个,
- 什么是二级索引、聚簇索引、覆盖索引?
- 关系数据库中用 CREATE INDEX 创建的就是二级索引,二级索引的索引值不一定唯一,InnoDB 二级索引的值存的是相关行的主键,Postgres 存的是磁盘位置的引用(堆文件)。
- 如果实际数据(行、文档、顶点)直接存储在索引中,那么就是聚簇索引,mysql InnoDB 主键索引就是聚簇索引。
- 两者的折中是覆盖索引,或称包含列的索引,在索引中存储了某些列,这就允许直接用索引回答查询而无需解析主键或查看堆文件。
- 什么是全内存存储?
- 内存数据库避免了将内存数据结构编码为写入磁盘的形式的开销,毕竟磁盘数据库也能把数据缓存在内存中。
- 一些内存数据库对于重启机器丢失数据是接受的如 Memcached,另一些内存数据库旨在实现持久性,通过电池供电的 RAM、更改日志写入磁盘、定期快照写入磁盘、复制内存状态到其他机器等方式来实现

存储与检索
加载中...
- 红黑树、跳表介绍 & 同类有序结构
- 红黑树
- 一种自平衡二叉查找树,通过颜色规则(红 / 黑)+ 旋转保证树高始终为
O (log n) - 核心约束:根节点黑、红节点子节点必黑、任意节点到叶子路径黑节点数相同
- 特点:查询 / 插入 / 删除均为
O(log n),内存结构,适合频繁读写、随机查找 - 典型使用:C++ STL map/set、Java TreeMap
- 一种自平衡二叉查找树,通过颜色规则(红 / 黑)+ 旋转保证树高始终为
- 跳表(Skip List)
- 基于有序链表 + 多层索引实现的有序结构,用 “跳步” 加速查找
- 每层都是原链表的子集,高层索引跨度更大,查找时从高层往下逼近
- 特点:实现简单、并发友好,查询 / 插入 / 删除
O (log n) - 典型使用:Redis SortedSet、LevelDB 内部索引
- 红黑树
- 类似的有序数据结构
- 平衡二叉树类:AVL 树、2-3 树、2-3-4 树
- 哈希 + 有序类:LinkedHashMap(Java)、OrderedDict(Python)
- 多路平衡查找树:B 树、B+ 树、B* 树
- 其他:treap(树堆)、splay tree(伸展树)、笛卡尔树
该算法最初于 1996 年以 日志结构合并树 ( Log-Structured Merge-Tree )或 LSM 树 ( LSM-Tree ) 的名称发布,建立在早期日志结构文件系统工作的基础上。因此,基于合并和压实排序文件原理的存储引擎通常被称为 LSM 存储引擎 。
- LSM = Log-Structured Merge Tree,日志结构合并树,这是一个算法,就是上面提到的日志结构存储,不是具体的某种树结构。核心思想:
- 写入不直接修改磁盘,先写内存 + 日志
- 内存满了再批量刷到磁盘形成有序文件
- 后台异步合并多个磁盘文件,减少小文件
- 适合极高写入吞吐,查询略慢(需多层查找)
- 典型使用:LevelDB、RocksDB、HBase、Cassandra、TiKV 等。
- B 树 / B+ 树
- 经典磁盘友好的多路平衡查找树
- B 树:键值存在所有节点,叶子非链表
- B+ 树:键只在叶子节点,叶子形成有序链表
- 适合读多写少、强事务、随机查询
- 典型使用:MySQL InnoDB 索引、PostgreSQL、SQL Server
- B + 树适合 “读多、稳定、强事务”,LSM 树适合 “写爆、高吞吐、可接受略慢查询” 的场景。
复制 复制
- 复制为了什么?故障仍可用、地理上接近用户、读副本增加吞吐量
- 复制与备份的区别是什么?备份是存旧快照可回滚,复制是数据的实时同步
- 复制的核心算法主要有哪三种?
- 单主复制:一个副本是主节点,其余的是从节点;写入发送给主节点,其余节点通过主节点发送的复制日志应用所有写入,mysql 中的 binlog 逻辑日志,raft 基于单主节点;
- 什么是同步复制、异步复制?同步复制是主节点等从节点确认,异步复制是主节点发送变更后直接让客户端报告成功
- 不停机设置新副本的核心流程是什么?先从主节点复制快照,然后追上快照拍摄后的写入
- 节点故障怎么处理?主节点故障:故障转移;从节点故障:追赶恢复
- 复制日志如何实现?基于语句、基于预写日志、基于逻辑日志(基于行)
- 多主复制:多个节点同时接收写入,也同时是其他主节点的从节点,特别适合跨地域的地区之间主节点互相复制、本地优先的一些软件
- 多主复制有哪些拓扑结构?双主节点拓扑、环形拓扑、星形拓扑、全对全拓扑
- 写入冲突时如何处理?不同主节点上的并发写入,并发定义为写入发生时,两个写入互相不知道对方的存在
- 最后写入者胜 LWW:丢弃并发写入,本质是随机选一个写入
- 手动冲突解决:数据库存所有写入值为兄弟节点,查询时返回所有,让程序自动或用户手动合并,最后写回新值解决冲突
- 自动冲突解决:操作变换、无冲突复制数据类型
- 无主复制:放弃主节点概念,任何副本都能接受写入
- 写入时并行发送到 n 个副本,收到 w 个节点的确认就认为写入成功;读取时并行发送到 n 个副本,等待r个节点的响应,通过版本号/时间戳区分最新值
- 读写仲裁:当w + r > n时,读取的r个节点与写入的w个节点必然存在重叠,可保证读取到最新值
- 单主复制:一个副本是主节点,其余的是从节点;写入发送给主节点,其余节点通过主节点发送的复制日志应用所有写入,mysql 中的 binlog 逻辑日志,raft 基于单主节点;
- 复制延迟的问题:单主复制+异步复制+读扩展
- 最终一致性:异步从节点落后时客户端读到过时信息,停止写入并等待后最终从节点会赶上主节点,达成数据一致;这种复制延迟在正常操作时为几分之一秒,系统高负载或网络故障时会长达几秒甚至几分钟。
- 复制延迟引起的三大核心异常
- 读己之写(写后读):用户写入后立即查看,异步从节点尚未同步,用户看不到提交的数据 —> 1min 内读主节点/同步副节点;客户端记录最近写入的时间戳;—> 用户始终能看到自己提交的更新,但不对其他用户的更新可见性做承诺
- 单调读:用户多次读取路由到不同副本,先看到最新数据后看到过时数据,发生时间倒退 —> 确保多次读同一个副本 —> 用户多次读不会看到时间倒退
- 一致前缀读:分片数据库中,因果相关的写入,不同分片复制延迟不同,用户先看到结果后看到原因 —> 确保因果相关的写入都写入同一个分片 —> 按特定顺序发生的写入,在读取时也是相同的顺序,不会因果倒置
- 并发写入检测与版本控制:多主、无主复制时并发写入导致副本不一致
- 这里的并发与物理时间有关系吗?与物理时间是否重叠无关,核心是信息是否可达。
- 通过算法判断两个操作是否并发;先发生的操作应覆盖之前的操作,并发操作需触发冲突解决。
复制
加载中...
分片 分片
- 分片是什么?单机无法承载,不一定要在每个节点保存所有数据,可以将大量数据划分为更小的分片(分区),不同的分片存在不同的节点上,优势在于可水平扩展、负载并行,劣势在于复杂、关系数据处理难、事务问题。
- 键值数据分片的常见策略有哪些?
- 范围分片:按 ID、时间、区域等连续范围切分,但易热点、数据倾斜
- 哈希分片:对 key 做 hash 后取模,但扩缩容要重新 hash 大量数据迁移
- 一致性哈希:虚拟节点解决倾斜,节点变化迁移量最小
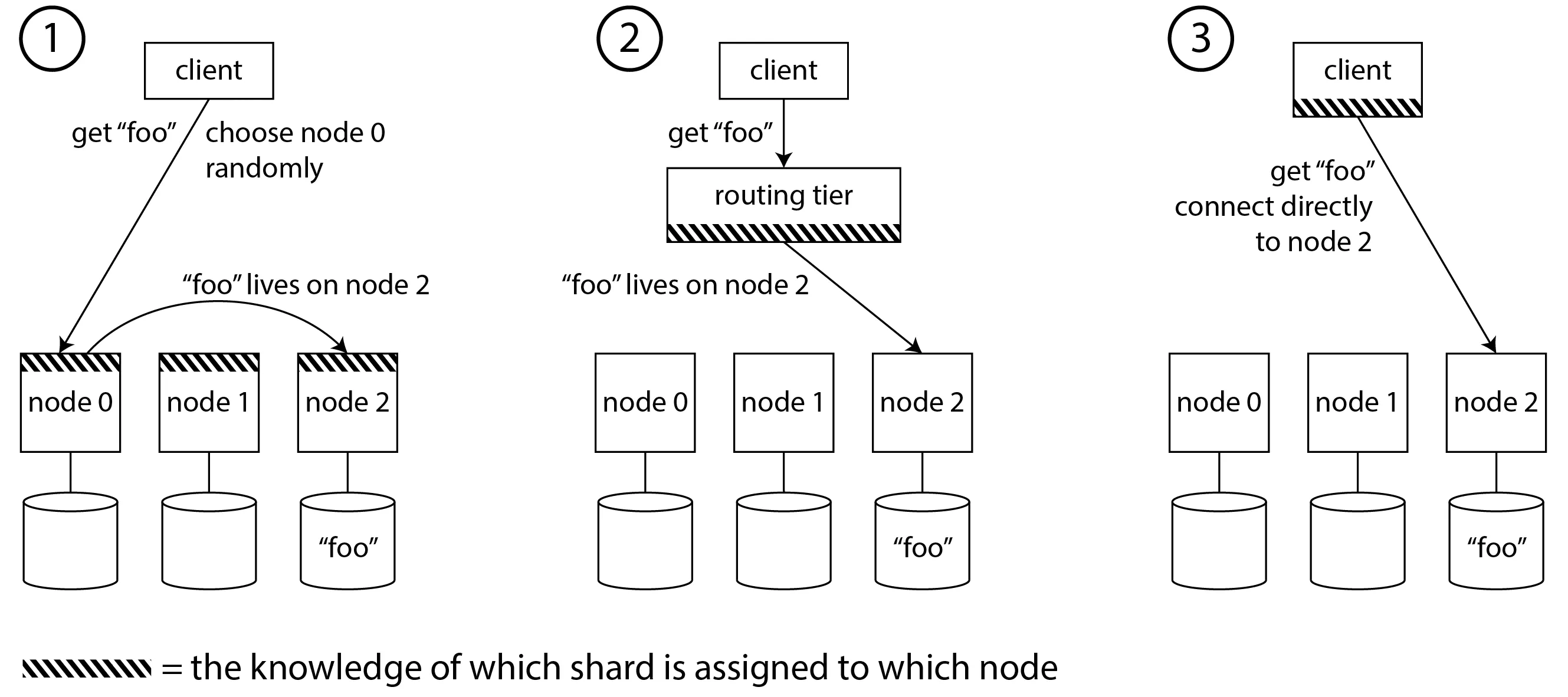
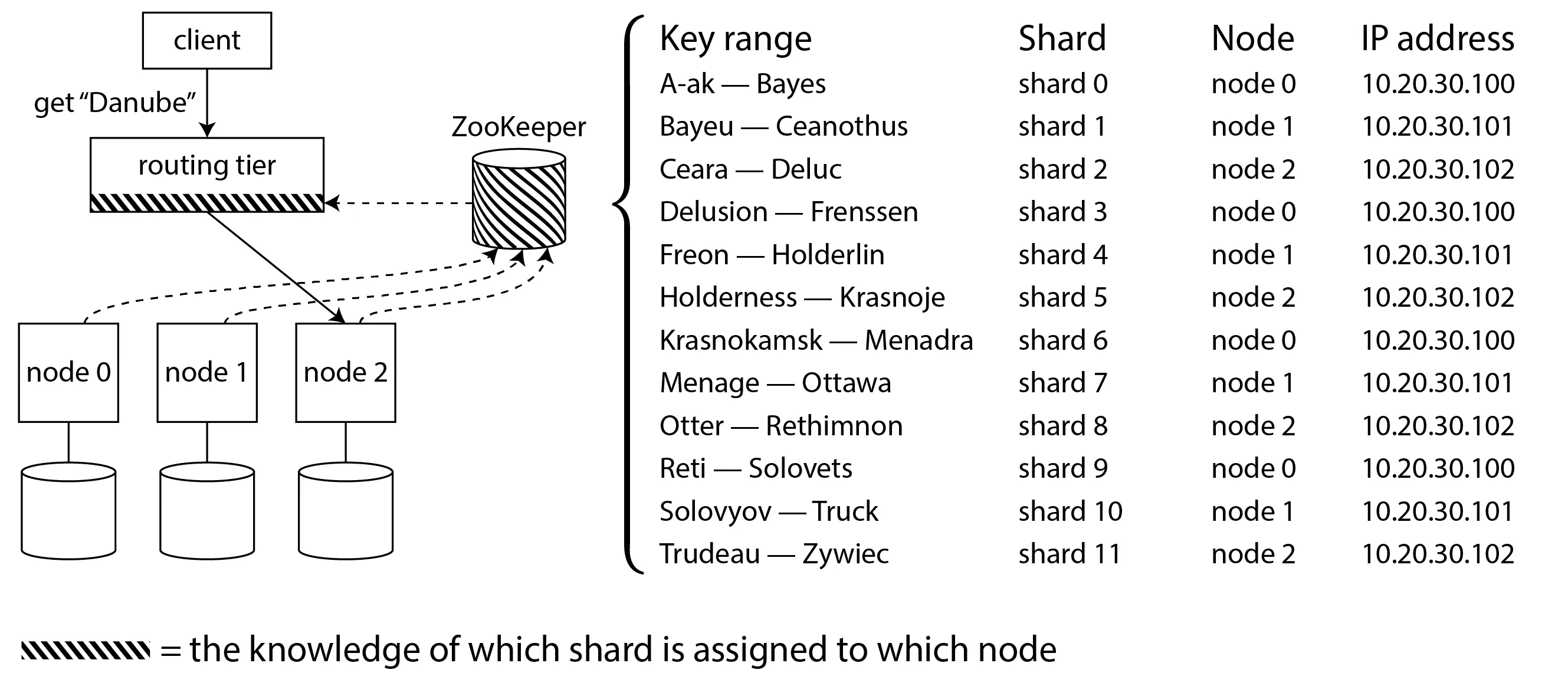
- 读写时如何定位节点?请求路由问题:
- 客户端直连任何节点,请求转发
- 路由层负载均衡器转发
- 客户端直连确定节点,客户端知晓分片在节点上的分配
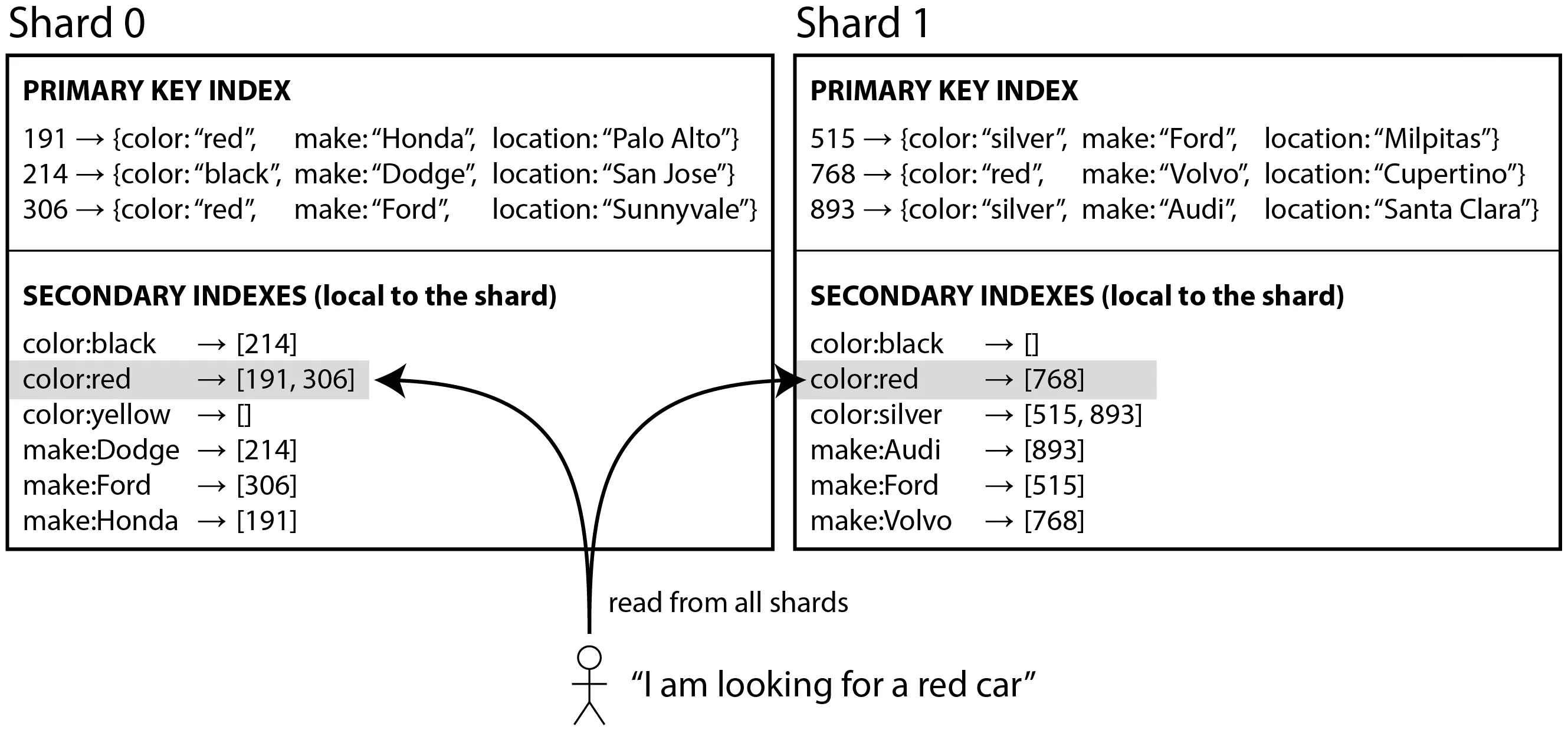
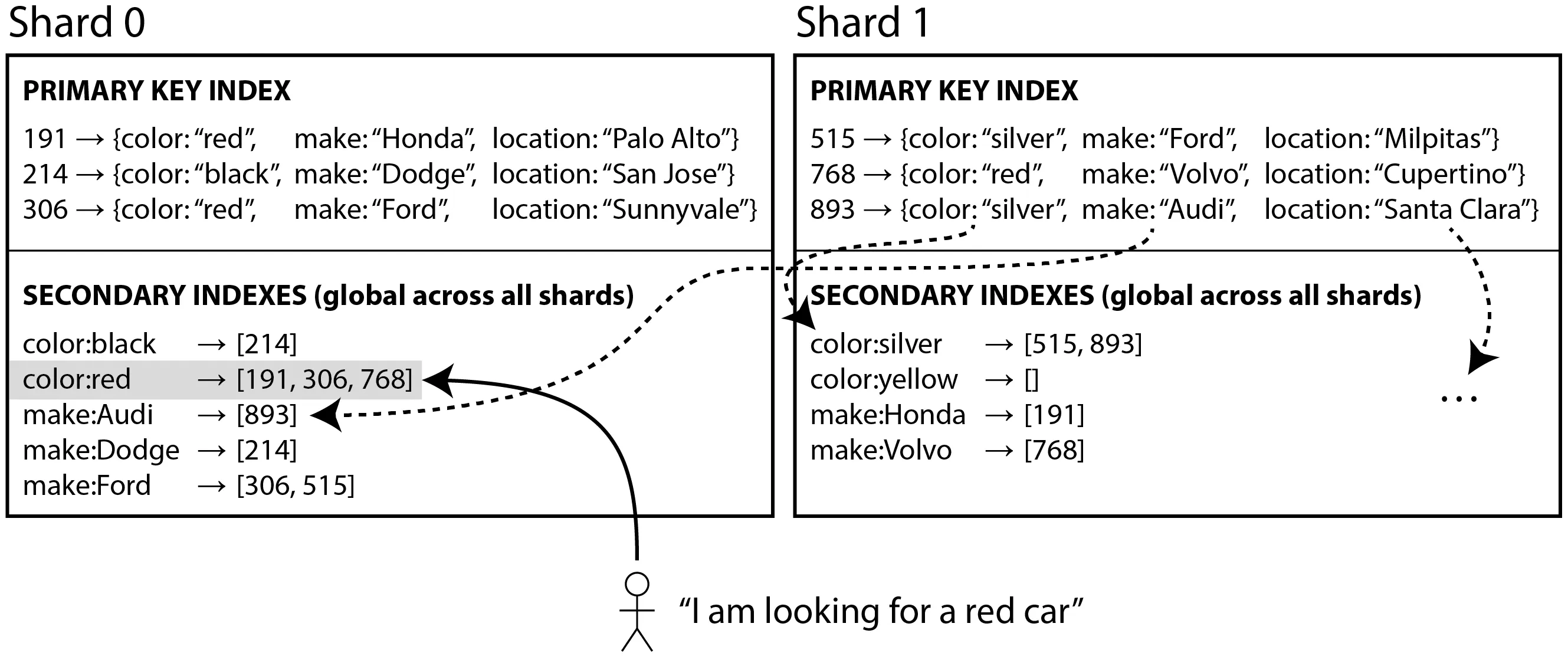
- 二级索引怎么办?
- 本地二级索引:每个分片只索引其自己分片内的记录,读取时需要分散查询,例如 ES
- 全局二级索引:索引覆盖全部分片,索引自身也会分片,写入时需要涉及多个分片,同步复杂,例如 TiDB
分片
加载中...
事务 事务
- MySQL 默认存储引擎 InnoDB 的默认事务隔离级别为:REPEATABLE READ(可重复读),简称 RR。注:MyISAM 等不支持事务的存储引擎,没有隔离级别概念。
- MySQL 四大隔离级别(从低到高):SQL 标准定义了4种隔离级别,InnoDB 全部支持。
- READ UNCOMMITTED(读未提交):最低级别,能读到未提交的脏数据(脏读),几乎不用。
- READ COMMITTED(读已提交,RC):只能读到已提交的数据,解决脏读,允许不可重复读。
- REPEATABLE READ(可重复读,RR):✅ MySQL 默认,解决脏读+不可重复读;MySQL 还通过 MVCC+临键锁 额外解决了幻读(优于标准 SQL)。
- SERIALIZABLE(串行化):最高级别,事务串行执行,无并发问题,但性能极差,极少使用。
- 实用补充:
- 生产环境优化:互联网公司通常会把默认级别改为 READ COMMITTED(RC),锁粒度更小、并发性能更高。
- 修改临时隔离级别(当前会话生效):
SET SESSION transaction_isolation = 'READ-COMMITTED';
- 临键锁(Next-Key Lock) 是 MySQL InnoDB 引擎在 REPEATABLE READ(RR) 隔离级别下默认使用的行级锁算法,本质是 记录锁(Record Lock)+间隙锁(Gap Lock) 的组合体。它不仅锁定具体的索引记录,还会锁定该记录之前的间隙,防止新记录插入,从而彻底解决幻读问题。
锁类型 作用 锁定范围 触发场景 作用 记录锁(Record Lock) 防止同一行被并发修改/删除:只锁这一行,不锁间隙 仅锁定具体索引记录本身 唯一索引等值查询(值存在) 防行并发修改 间隙锁(Gap Lock) 防止在间隙中插入新记录:只锁 “空白区间”,不锁任何真实行 锁定两个索引值之间的空白区域,不包含记录本身 唯一索引等值查询(值不存在) 防插入 临键锁(Next-Key) 组合防护,解决幻读:既锁行,又锁前面的间隙 左开右闭区间: (prev_value, current_record],既锁记录又锁间隙非唯一索引 / 范围查询 防幻读 - 锁定范围与规则
- 临键锁遵循左开右闭原则,锁定区间为
(a, b],例如:- 当索引值存在 10、13、17 时,查询
WHERE age = 13会锁定 age 索引上(10, 13]区间 - 范围查询
WHERE age BETWEEN 10 AND 20会锁定锁定 age 索引上(10,13]、(13,17]、(17,20]多个区间(范围查询会把所有匹配区间全部上临键锁。)
- 当索引值存在 10、13、17 时,查询
- 临键锁遵循左开右闭原则,锁定区间为
- 在 RR 隔离级别下,InnoDB 的加锁原则如下:
- 默认单位:加锁的基本单位是临键锁(Next-Key Lock)。
- 锁退化(优化):
- 如果是唯一索引等值查询且记录存在,锁退化为记录锁(Record Lock)。
- 如果是唯一索引等值查询但记录不存在,锁退化为间隙锁(Gap Lock)。
- 非唯一索引/范围查询:始终使用完整临键锁
- 等值查询:对匹配的记录加记录锁,并加间隙锁(防止幻读)。
- 范围查询:使用临键锁。
- 适用范围:上述规则适用于
SELECT ... FOR UPDATE、UPDATE、DELETE等当前读操作。FOR UPDATE只是 “加锁指令”,具体加什么锁,看查询条件- 能乐观锁(版本号)解决的,尽量不用悲观锁
FOR UPDATE。 - 一定要走索引,没索引会锁全表,直接把业务堵死。
- 隔离级别是“目标”,而加锁是实现这个目标的“手段”之一。隔离级别定义了一个事务能看到其他事务操作的程度(即数据可见性规则),而数据库为了实现这些规则,会根据不同的隔离级别,采取不同的加锁策略。
- MySQL 的 InnoDB 引擎主要通过两种技术来实现隔离级别:锁(Locking) 和 多版本并发控制(MVCC)。
- MVCC:一种“无锁”的并发控制机制。它通过保存数据的历史版本,让读操作可以去读一个“快照”,而不需要加锁。这极大地提升了读写并发的性能。
- 锁:传统的并发控制机制,通过锁定资源来阻止其他事务的访问。
隔离级别 普通 SELECT(快照读)SELECT ... FOR UPDATE/SHARE/UPDATE/DELETE(当前读)核心实现机制 读未提交 (RU) 不加锁 加行级排他锁 (X锁) 读不加锁,写加锁 读已提交 (RC) 不加锁 (使用MVCC) 加行级排他锁 (X锁),不加间隙锁 MVCC + 行锁 可重复读 (RR) 不加锁 (使用MVCC) 加行级排他锁 (X锁) + 间隙锁 (Gap Lock) MVCC + 临键锁 串行化 (Serializable) 自动加共享锁 (S锁) 加行级排他锁 (X锁) 锁机制 - 在 RC 和 RR(MySQL默认)这两个最常用的隔离级别下,普通的 SELECT 查询都不会加锁,而是利用 MVCC 来实现高并发读取。
- 只有在最高的 Serializable 隔离级别下,普通的 SELECT 才会自动加锁(共享锁),因为它要求事务完全串行执行。
- 什么情况下会加锁?
- 加锁主要发生在“当前读”的场景中,即需要读取数据的最新版本,或者要修改/删除数据时。
- 显式加锁查询:
SELECT ... FOR UPDATE:给读取的行加上排他锁 (X锁)。其他事务不能读写这些行。SELECT ... LOCK IN SHARE MODE或者SELECT ... FOR SHARE:给读取的行加上共享锁 (S锁)。其他事务可以读,但不能修改。
- 写操作 (DML):这是最常见的“默认加锁”情况。任何对数据的修改操作,在执行时都会自动对涉及的数据行加上排他锁 (X锁)。
UPDATE…DELETE…INSERT…
- 特殊情况:
- 外键约束检查:在删除或更新父表记录时,InnoDB 会对子表的相关记录加共享锁进行检查。
- 唯一性约束检查:在插入数据时,为了检查唯一索引是否冲突,可能会对相关的索引记录加锁。
- 加锁的粒度
- 记录锁 (Record Lock):只锁住具体的某一行记录。这是最理想的锁。
- 间隙锁 (Gap Lock):锁住一个索引范围(间隙),但不包括记录本身。主要用于防止“幻读”。
- 临键锁 (Next-Key Lock):记录锁 + 间隙锁的组合。在 RR 隔离级别下,范围查询(如 WHERE id > 10)会使用临键锁,锁住扫描到的所有索引区间。
- 退化为表锁:这是一个性能陷阱!如果
UPDATE、DELETE或SELECT ... FOR UPDATE的WHERE条件没有用到索引,InnoDB 无法精确定位到行,就会进行全表扫描,并锁住整张表的所有行。这会严重阻塞其他所有事务,导致系统性能急剧下降。
MVCC (多版本并发控制) 是现代数据库(如 MySQL 的 InnoDB、PostgreSQL、Oracle)中用于实现高并发访问的核心机制。简单来说,它的核心思想是:通过保存数据的历史版本,让“读”操作不需要加锁,从而实现“读写不冲突”。
- 为什么要用 MVCC?(解决什么问题)
- 在传统的数据库锁机制中:
- 读操作需要加共享锁(S锁)。
- 写操作需要加排他锁(X锁)。
- 冲突:只要有人在写数据,其他人就不能读;只要有人在读数据,其他人就不能写。这会导致并发性能很差。
- MVCC 的出现就是为了解决这个问题:
- 读不阻塞写:你在读数据时,我可以修改它。
- 写不阻塞读:我在修改数据时,你依然可以读到修改前的旧版本(快照)。
- 在传统的数据库锁机制中:
- MVCC 的核心原理(它是如何工作的)
- MVCC 的实现依赖于三个核心组件(以 MySQL InnoDB 为例):
- 隐藏字段
- InnoDB 会在每一行数据后面自动添加几个隐藏列:
DB_TRX_ID:记录最近修改这行数据的事务 ID。DB_ROLL_PTR:回滚指针,指向这行数据的旧版本(在 Undo Log 中)。
- InnoDB 会在每一行数据后面自动添加几个隐藏列:
- Undo Log(回滚日志)
- 当你更新一行数据时,InnoDB 不会直接覆盖原数据,而是:
- 把旧数据写入 Undo Log。
- 生成新数据。
- 通过
DB_ROLL_PTR把新旧数据串联起来,形成一个版本链。
- 当你更新一行数据时,InnoDB 不会直接覆盖原数据,而是:
- ReadView(读视图)
- 这是 MVCC 的“灵魂”。当一个事务进行查询时,它会生成一个 ReadView。ReadView 里记录了当前系统中所有活跃(未提交)的事务 ID 列表。
- 查询时的逻辑(可见性算法):
- 当事务 A 查询数据时,拿着自己的 ReadView 去对比数据行上的
DB_TRX_ID:- 如果数据行的
DB_TRX_ID在 ReadView 的活跃列表中(说明修改者还没提交),那就顺着DB_ROLL_PTR去找旧版本。 - 一直找到第一个“已提交”的版本,返回给你。
- 如果数据行的
- 就像你在看一本书(数据库),虽然作者(写事务)正在涂改书页,但你手里拿的是作者刚涂改前拍的一张“照片”(ReadView/快照)。你依然可以安心读你的照片,而作者可以在原书上随意修改,互不干扰。
- 当事务 A 查询数据时,拿着自己的 ReadView 去对比数据行上的
- 查询时的逻辑(可见性算法):
- 这是 MVCC 的“灵魂”。当一个事务进行查询时,它会生成一个 ReadView。ReadView 里记录了当前系统中所有活跃(未提交)的事务 ID 列表。
- 隐藏字段
- MVCC 的实现依赖于三个核心组件(以 MySQL InnoDB 为例):
- 两种读取模式,在 MySQL 中,查询分为两种,决定了是否使用 MVCC:
模式 说明 是否加锁 典型 SQL 快照读 读取数据的历史版本(快照),不加锁,速度最快。 否 SELECT * FROM table ...当前读 读取数据的最新版本,并加锁,防止并发修改。 是 SELECT ... FOR UPDATEUPDATEDELETEINSERT - 隔离级别与 MVCC 的关系:MVCC 主要应用在 READ COMMITTED (RC) 和 REPEATABLE READ (RR) 这两个隔离级别中。它们的区别在于 ReadView 生成的时机不同:
- READ COMMITTED (读已提交):
- 策略:每次执行 SELECT 时都生成一个新的 ReadView。
- 效果:你能看到其他事务已经提交的最新数据。
- 问题:同一个事务内,两次 SELECT 可能读到不一样的数据(不可重复读)。
- REPEATABLE READ (可重复读,MySQL 默认):
- 策略:第一次执行 SELECT 时生成 ReadView,后续复用这个 ReadView。
- 效果:不管别人怎么修改并提交数据,你在整个事务期间看到的都是事务开始时的数据快照。
- 优势:解决了“不可重复读”问题。
- READ COMMITTED (读已提交):
- MVCC 的优缺点
- 优点:
- 极高的并发性能:读写互不阻塞,特别适合“读多写少”的场景(如电商浏览商品详情)。
- 避免死锁:因为普通的 SELECT 不加锁,减少了死锁发生的概率。
- 缺点:
- 占用存储空间:需要维护 Undo Log 和历史版本数据。
- 维护成本:如果历史版本太多,查询时需要沿着版本链回溯,会影响性能。数据库需要后台线程(Purge)来清理过期的旧版本。
- 优点:
| 维度 | Redo Log (重做日志) | Undo Log (回滚日志) | Binlog (二进制日志) |
|---|---|---|---|
| 所属层级 | InnoDB 引擎层 | InnoDB 引擎层 | MySQL Server 层 |
| 核心目标 | 持久性 (宕机不丢数据) | 原子性 (回滚) + MVCC (历史版本) | 复制 + 恢复 |
| 记录内容 | 物理日志 (数据页的物理修改) | 逻辑日志 (反向操作,如 INSERT 变 DELETE) | 逻辑日志 (SQL 语句或行变更事件) |
| 写入方式 | 循环写 (文件固定大小,覆盖旧日志) | 随机写 (存储在表空间中,用完清理) | 追加写 (文件只增不减) |
| 适用场景 | 崩溃恢复 (Crash Recovery) | 事务回滚、快照读 | 主从同步(Relay Log 中继日志,专用于主从复制中的从库)、全量备份+增量恢复 |
MVCC 就是用“空间换时间”的策略——通过保存数据的历史版本(Undo Log),让读操作可以去读旧版本,从而避免了加锁,极大地提升了数据库的并发处理能力。
- 悲观锁:我觉得一定会有人跟我抢,所以我先锁住,再操作
- 事务里
FOR UPDATE锁住行 → 逻辑计算 → UPDATE - 绝对安全,不会并发错误,但锁持有时间长,并发差,容易死锁、阻塞
BEGIN; -- 先锁 A 账户(FOR UPDATE 排他锁) SELECT balance FROM user_account WHERE uid = 'A' FOR UPDATE; -- 逻辑校验余额足够 -- 扣 A 钱 UPDATE user_account SET balance = balance - 100 WHERE uid = 'A'; -- 锁 B 账户 SELECT balance FROM user_account WHERE uid = 'B' FOR UPDATE; -- 加 B 钱 UPDATE user_account SET balance = balance + 100 WHERE uid = 'B'; COMMIT;
- 事务里
- 乐观锁:我觉得没人跟我抢,所以先不加锁,直接改,改的时候再校验
- 核心实现:加一个
version版本号字段(也可以用update_time这种字段)- 每次修改,版本号 + 1
- 修改时校验:版本号没变,说明没人动过,修改成功;变了就失败重试
-- 1. 先查数据和版本号(无锁) SELECT stock, version FROM goods WHERE id=1; -- 2. 直接更新,同时校验版本号 UPDATE goods SET stock=stock-1, version=version+1 WHERE id=1 AND version=刚才查到的版本号; -- 3. 业务上检查 -- 如果更新行数 = 1 → 成功 -- 如果 = 0 → 说明别人改了,重试即可 - 不加锁,无阻塞,并发性能极高,只有写冲突时才重试,大部分场景效率远高于悲观锁;乐观锁是业务层实现的逻辑,数据库本身不提供这个功能,完全靠你自己加字段、写 SQL 来控制。
- 读多写少、冲突少 → 用乐观锁
- 写冲突极高、必须强一致 → 用悲观锁
FOR UPDATE
- 核心实现:加一个
- 在互联网、电商、后端主流业务里:乐观锁用得远远更多(占 90% 以上),悲观锁(
FOR UPDATE)只在少数强一致、低并发场景才用。
| 关注点 | 常见误区 | 推荐实践 | 核心理由 |
|---|---|---|---|
| 表设计 | 大宽表,所有字段一张表 | 垂直拆分,冷热分离 | 提高内存利用率,减少 IO |
| 字段类型 | 全文 VARCHAR(255),金额用 DOUBLE | 精准匹配,金额用 DECIMAL | 节省存储,保证精度 |
| 索引 | 索引越多越好,乱建联合索引 | 最左前缀,区分度优先 | 平衡读写性能,避免无效索引 |
| SQL操作 | 无 WHERE 更新,物理 DROP | 软删除,权限最小化 | 防止人为误操作导致灾难 |
| 架构 | 单机裸奔,直接连生产库 | 主从复制,连接池,在线 DDL | 保证高可用与扩展性 |
事务
加载中...
批处理 批处理
批处理
加载中...
流处理 流处理
流处理
加载中...
