
Kafka权威指南 by Gwen Shapira & Todd Palino & Rajini Sivaram & Krit Petty
Kafka权威指南
目录
初识 Kafka 初识 Kafka
Kafka 自 4.0 版本起彻底移除对 ZooKeeper 的依赖,核心是 ZooKeeper 的局限性已成为 Kafka 规模化发展的瓶颈,替换为自研的 KRaft(Kafka Raft)架构:
- 可扩展性存在硬上限:ZooKeeper 自身仅支持 3-5 个节点,无法随 Kafka 集群线性扩容
- 性能与资源开销巨大:每个 Broker 需与 ZooKeeper 保持长连接和心跳,数千个 Broker 可压垮小型 ZooKeeper 集群
- 一致性模型不匹配,易出现状态异常:元数据同时存储在 ZooKeeper(持久化)和 Kafka Controller 内存(运行时),易出现两者不一致,引发脑裂、副本选主错误、消息丢失或重复等问题
- 运维复杂度高,云原生不友好:需同时部署、监控、升级 Kafka 和 ZooKeeper 两个独立系统,运维成本翻倍
- 架构适配性差:ZooKeeper 是通用分布式协调工具,而 Kafka 需要的是专用、高效的内嵌元数据引擎,两者设计范式不匹配
KRaft 架构以 “元数据即日志” 为核心,将元数据变更写入内部特殊主题 __cluster_metadata,通过 Raft 协议实现元数据管理,解决了上述所有痛点,使 Kafka 支持百万级分区,故障恢复时间缩短至秒级。
KRaft 仅改变元数据管理方式,Kafka 核心特性(消息存储、副本机制、ISR、生产者 / 消费者逻辑等)完全不变。
初识 Kafka
加载中...
Kafka生产者——向Kafka写入数据 Kafka生产者——向Kafka写入数据
- 发送消息的基本流程是怎样的,经过了哪些组件?
- 3 种消息发送方式
- 发送并忘记:send 后就不管了,发送后的异常无感知
- 同步发送:send 会返回 Future,get()主线程会阻塞,生产环境极少用
- 异步发送:send 会指定回调,服务器响应时触发
- acks 配置影响消息持久性,0、1、all 分别代表了什么?
- 使用序列化器的意义?必须要有这一步吗?
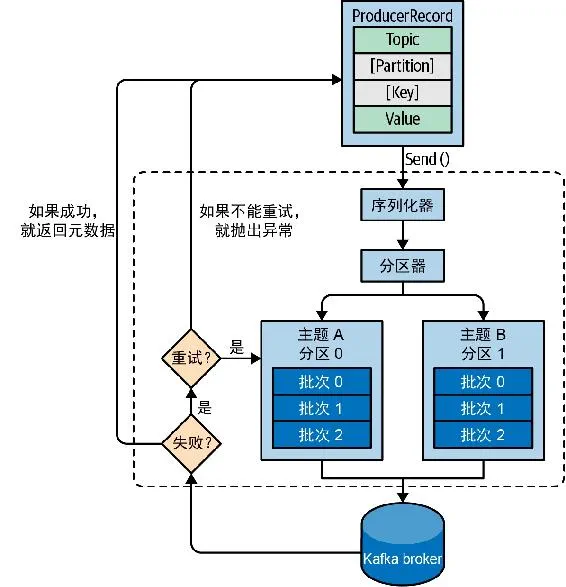
- Kafka 的Broker 端、网络传输、磁盘存储只识别字节数组(byte []),不识别 Java/Python/Go 等语言的对象、字符串、实体类,序列化器就是完成 「业务对象 → 字节数组」 转换的核心组件
- 网络传输适配:网络协议只传输二进制字节流,Java 对象、POJO、字符串无法直接通过 Socket 发给 Kafka Broker,必须转字节。
- 存储格式统一:Kafka 持久化消息到磁盘、副本同步,均以字节形式存储,无序列化则无法落盘。
- 跨语言 / 跨平台兼容:生产者用 Java、消费者用 Go/Python 时,字节是通用格式,序列化能屏蔽语言差异。
- 体积优化与性能提升:二进制序列化(Avro/Protobuf)比纯文本更小,传输更快、吞吐量更高。
- 必须做序列化,没有例外。Kafka 生产者协议强制要求消息的键(Key)和值(Value)必须是字节数组,哪怕你只发简单字符串,也会通过 StringSerializer 转字节;如果不配置序列化器,直接抛 SerializationException 异常,消息根本无法发送。
- Kafka 的Broker 端、网络传输、磁盘存储只识别字节数组(byte []),不识别 Java/Python/Go 等语言的对象、字符串、实体类,序列化器就是完成 「业务对象 → 字节数组」 转换的核心组件
- Avro 序列化的特点
- Apache Avro 是 Kafka 生态最主流的序列化方案,核心特点:
- Schema(模式)驱动:用 JSON 定义数据结构,序列化后是二进制格式,体积远小于 JSON 文本。
- 极佳的兼容性:模式增删字段、修改类型时,新旧生产者 / 消费者无需修改代码即可兼容,不会出现解析异常。
- 语言无关:支持 Java/Go/Python 等所有主流语言,跨平台无压力。
- 支持默认值:字段缺失时自动使用默认值,不会丢失数据。
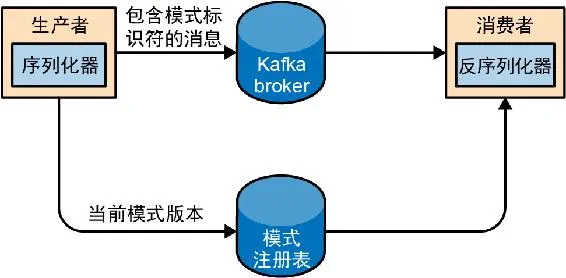
- 结合 Schema Registry(模式注册表):模式统一存储,消息只带模式 ID,大幅减少消息体积,避免每条消息内嵌完整模式。
- 动态类型:无需提前编译生成实体类,支持通用 GenericRecord 动态解析。
- Avro 与主流序列化框架对比:Kafka 生产环境优先选 Avro,追求极致性能选 Protobuf。
序列化框架 序列化形式 体积 兼容性 性能 依赖 Schema Kafka 生态适配 Avro 二进制 极小 最优(动态兼容) 高 强依赖 原生支持,官方推荐 Protobuf 二进制 小 好(需编译) 极高 强依赖 适配性好 Thrift 二进制 小 好 高 强依赖 通用,非 Kafka 首选 JSON 文本 大 差(字段变更易报错) 低 无 简单场景可用 Java 原生序列化 二进制 大 极差 低 无 严禁在 Kafka 使用
- Apache Avro 是 Kafka 生态最主流的序列化方案,核心特点:
- 代码中的 JSON 序列化 vs Kafka 消息序列化
- 代码中的 JSON 序列化(普通业务层)
- 本质:Java 对象 → JSON 字符串(文本格式)
- 目的:接口传输、日志打印、前端交互
- 特点:体积大、无 Schema、兼容性差、仅做文本转换
- 结果:最终还是要通过 Kafka 的 StringSerializer 再转字节数组才能发送
- Kafka 消息序列化(协议层)
- 本质:任意对象 → 字节数组(二进制 / 文本字节)
- 目的:满足 Kafka 网络传输、存储、跨语言的协议要求
- 特点:
- 最终输出一定是 byte[],而非字符串
- 支持二进制压缩(Avro/Protobuf),体积更小
- 配套反序列化器,严格保证消费端解析
- 可结合 Schema 做兼容、校验
- 层级关系:JSON 序列化是业务层转换,Kafka 序列化是协议层强制转换
- 代码中的 JSON 序列化(普通业务层)
- 消息投递语义是Kafka 生产者 / 消费者 与 Broker 之间,消息投递的可靠性承诺,描述「消息到底会被投递几次、会不会丢、会不会重复」,Kafka 有三大核心投递语义:
- 最多一次(At Most Once):消息最多被投递 1 次,可能丢失,绝不会重复
- 生产者配置:
acks=0+ 关闭重试(acks规定 Kafka 服务器需要完成多少份数据备份,才告诉生产者「消息发送成功了」) - 行为:生产者发完消息不等待 Broker 响应,网络异常、Broker 宕机都会丢消息
- 适用场景:日志采集、监控指标(允许少量丢失,追求极致吞吐量)
- 生产者配置:
- 至少一次(At Least Once):绝不丢消息,但可能重复投递(工程上的「绝不」不代表宇宙级的「绝不」,消息不会无故丢失,生产者会重试,只要 Broker 正常就能收到)
- 生产者配置:
acks=1/all+ 开启重试(默认开启),acks=1在极端极端故障下存在理论丢消息可能,而不是日常会丢,acks=all把「最后那点理论丢消息风险」也彻底堵死了。 - 行为:Broker 没响应时生产者自动重试,可能导致 Broker 已写入但响应丢失,重复发送
- 适用场景:绝大多数业务场景(可通过业务幂等解决重复问题)
- 生产者配置:
- 精确一次(Exactly Once):消息既不丢失,也不重复,精准投递 1 次
- 生产者配置:
enable.idempotence=true(幂等生产者)+ 事务生产者 - 行为:Broker 对消息做序列号去重,重试不会产生重复消息
- 适用场景:金融交易、支付、对账(强一致性要求)
- 生产者配置:
- 最多一次(At Most Once):消息最多被投递 1 次,可能丢失,绝不会重复
acks=0:不等待任何确认,发完就走,风险:网络断了、Broker 挂了,消息直接丢
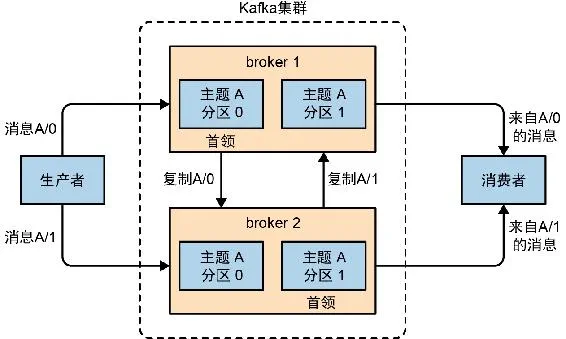
acks=1:只等「首领副本」确认写入,Kafka 分区有 1 个 Leader(首领)+ 多个 Follower(副本),风险:Leader 刚写完就挂了,副本还没同步 → 消息丢失
acks=all/acks=-1:等「所有同步副本」都写入成功才确认,所有在同步列表里的副本(ISR)都写完,才算成功,Kafka 3.0+ 默认值就是acks=all,速度最慢、延迟最高
acks控制的是:消息的可靠性 ↔ 吞吐量 的平衡
Kafka生产者——向Kafka写入数据
加载中...
