Neo4j: 图数据基本概念、语法与增删改查
目录
Neo4j 简介
Neo4j 使用属性图(Property Graph)模型1。
一个图包含节点(Objects)和边(Relationships)。
Neo4j 的属性图模型包含了:
- 节点
- 节点标签:用于区分节点的类型,0个或多个
- 边:源节点与目标节点之间的一条有向边
- 边类型:用于区分边的类型,有且仅有1个
- 属性:节点和边都可以有属性(键值对)用于描述节点和边
注意这些名词的英文:node、relationship、label(节点可以有0个或多个标签)、type(边只有一个类型)、property
在数学的图论中,node 也称 vertex、point,relationship 也称 edge、link、line。
属性图

上面这个图可以用 Cypher 语句这样表示:
CREATE (:Person:Actor {name: 'Tom Hanks', born: 1956})-[:ACTED_IN {roles: ['Forrest']}]->(:Movie {title: 'Forrest Gump'})<-[:DIRECTED]-(:Person {name: 'Robert Zemeckis', born: 1951})
Cypher 查询语言2,是 Neo4j 图查询语言,能让你从图中获取数据。类似图的 SQL ,也是被 SQL 启发的,让你能专注于你想要什么数据而不是怎么拿到它。目前,它是最易于学习的图语言,因为跟其他语言相似,并且很主观。
后面我们会详细介绍这门语言。可以看到,圆括号包裹了节点,而方括号包裹了边,还有类似ASCII艺术风格的箭头表示。
Cypher 可以说是 Neo4j 的主要接口。
节点 Node
节点被用来表示一个域的实体。
节点的标签 Label 用来区分实体类型,一个实体可以有0个或多个标签。
标签可以在运行时动态添加或删除,因此可以用来表示节点的临时状态。
不同的标签可以表达数据的不同维度。

建议节点标签命名用大驼峰,如
:VehicleOwner。3
边 Relationship
一条边描述了源点与目标点之间的关系。
边是有向边,并且必须有一个类型 Type 来区分是何关系。
边可以用很多属性即键值对,可用来进一步描述关系。
边可以与节点组装起来,形成一个结构,如链表、树、图、环、化合物等等。
要创建边,必须创建或引用节点。
边总是有方向的,但是这个方向在你不用的时候可以忽视。这意味着,你没必要添加相反方向的重复边,除非你认为这是必要的。
一个节点可以有指向自己的边。
一条边必须有一个确切的类型。

建议边类型用全大写+下划线,如
:OWNS_VEHICLE。3
属性 Property
属性就是键值对,用来存储节点或边的数据。
键类似变量,值可以是:
- 不同的数据类型,如数值、字符串、布尔值
- Integer, Float, String, Boolean, Point, Date, Time, LocalTime, DateTime, LocalDateTime, and Duration4.
- 同构的列表或数组,也就是元素类型都得相同
建议属性(值的键)用小驼峰,如
firstName。5更多命名习惯,请看 Naming rules and recommendations - Neo4j Cypher Manual。
模式 Schema
在 Neo4j 中模式指的是索引和约束。
Neo4j 的模式是可选的,意味着没必要创建索引和约束,你可以直接创建数据。
当然你也可以创建索引和约束来提升性能或是建模所带来的好处。
索引 Index
索引用于提升性能。主要就是用来找到遍历的起始点6。
一旦起始点找到了,遍历就依赖图的结构而能取得高性能。
索引可以在任何时候添加。
CREATE INDEX example_index_1 FOR (a:Actor) ON (a.name)
在大多数情况下,查询的时候不必指定索引,因为会自动选用合适的索引。
例如下面的语句将使用上面的索引:
MATCH (actor:Actor {name: 'Tom Hanks'})
RETURN actor
也存在复合索引:
CREATE INDEX example_index_2 FOR (a:Actor) ON (a.name, a.born)
查询有哪些索引:
SHOW INDEXES YIELD name, labelsOrTypes, properties, type
Rows: 2
+----------------------------------------------------------------+
| name | labelsOrTypes | properties | type |
+----------------------------------------------------------------+
| 'example_index_1' | ['Actor'] | ['name'] | 'BTREE' |
| 'example_index_2' | ['Actor'] | ['name', 'born'] | 'BTREE' |
+----------------------------------------------------------------+
约束 Constraint
约束用来保证数据是遵守了域的规则的。
例如唯一性约束:
CREATE CONSTRAINT constraint_example_1 FOR (movie:Movie) REQUIRE movie.title IS UNIQUE
约束可以在已有数据上添加,但要保证这些已有数据是服从这个约束的。
查询有哪些约束:
SHOW CONSTRAINTS YIELD id, name, type, entityType, labelsOrTypes, properties, ownedIndexId
Rows: 1
+----------------------------------------------------------------------------+
| id | name | type | entityType | labelsOrTypes | properties | ownedIndexId |
+----------------------------------------------------------------------------+
|4| 'constraint_example_1' | 'UNIQUENESS' | 'NODE' | ['Movie']| ['title']| 3 |
+----------------------------------------------------------------------------+
这个唯一性约束所有版本都支持,其他约束得在企业版中才能支持。
Cypher 语法视频介绍
介绍 Cypher 语法有一个视频,很不错。
https://www.youtube.com/embed/l76udM3wB4U





Cypher 基本语法
Cypher 基于 Pattern
模式(Pattern)由节点和边组成,并且可以表达简单或复杂的遍历或路径。
模式的识别是基础,而人们是擅长识别这些模式的,因此 Cypher 也基于模式来简化查询。
模式也是 AsciiArt,很直观。
注释
双斜线://
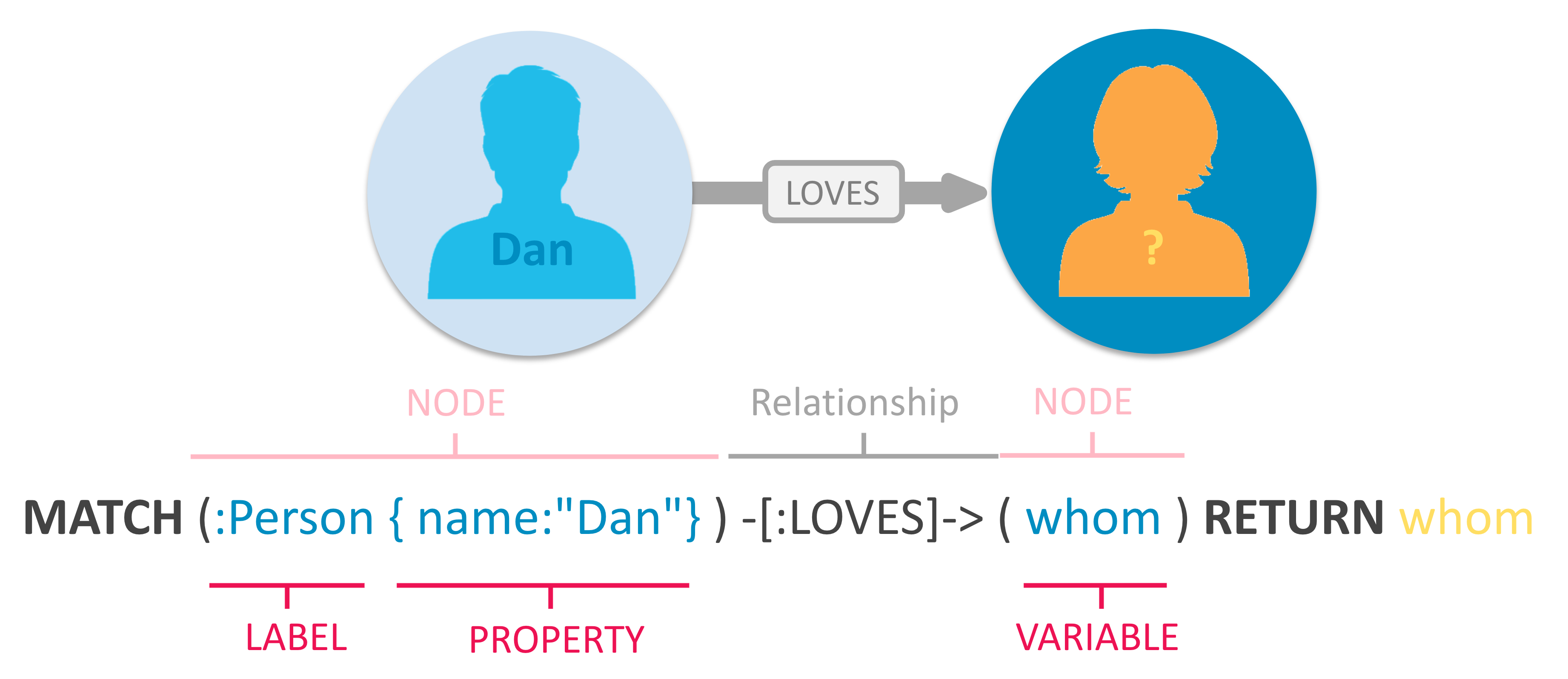
节点表示 Node
用圆括号包围一个节点:(node)。
为什么是圆括号?因为看起来像一个圆圆的节点啊。
举例:
() // 匿名节点,可指代任意节点
(p:Person) // 变量p与标签Person
(:Technology) // 无变量,标签Technology
(work:Company) // 变量work与标签Company
节点变量
如果之后想引用这个节点,那么我们可以对节点分配一个变量,命名就类似编程语言的变量命名。
如果节点与返回的结果并不相关,那么可以指定匿名节点即空括号(),这意味着之后不能返回这个节点。
节点标签
节点标签可以把相似的节点聚集起来。
就像 SQL 中选择特定的某张表。
如果不指定标签,就会查询所有节点,这真的很笨重。
边表示 Relationship
边在Cypher中使用箭头表示-->、<--。
边的属性可以用箭头中的方括号表示-[:LIKES]->。
无向图的边没有方向 --,这就表示任一方向的关系都可以被遍历到。这对忽略方向时的查询非常有用。
如果数据是有向边,那么当查询指定了错误的方向时返回的结果为空。在这种情况下,使用无向边来查询是合适的。
边类型
边类型对边增加了语义,展示了节点之间是为何相连的。
边类型最好是有语义的,如使用动词或动作。
边变量
就像节点变量一样,当我们想引用某个边时,可以设置变量,如[r]。
匿名边:--、-->、<--。
有变量的边:-[rel]->、-[rel:LIKES]->。
注意如果没有冒号的话就不是边类型了,而成了边变量。
属性 Property
属性就是键值对,对节点和边的细节进行描述。
这些属性使用花括号表示,很像Python的字典格式,可以放在节点中,也可以放在边中。
举例:
(p:Persion {name: 'Jack'})-[rel:IS_FRIENDS_WITH {since: 2018}]->()
模式 Pattern
模式可由节点和关系组成的构建块来表示。
这些构建块可以表达简单或复杂的模式。
模式可以写作连续的路径或由逗号分隔的离散的小模式串。
举例:
(p:Person {name: "Jennifer"})-[rel:LIKES]->(g:Technology {type: "Graphs"})